Performing with a Neural Touch-Screen Ensemble
03 May '17
Since about 2011, I’ve been performing music with various kinds of touch-screen devices in percussion ensembles, new music groups, improvisation workshops, installations, as well as my dedicated iPad group, Ensemble Metatone. Most of these events were recorded; detailed touch and gestural information was collected including classifications of each ensemble member’s gesture every second during each performance. Since moving to Oslo, however, I don’t have an iPad band! This leads to the question: Given all this performance data, can I make an artificial touch-screen ensemble using deep neural networks?

I’ve collected a lot of data from four years of touch-screen ensemble concerts (left). Now, I’ve used it to train an artificial neural network (right) to interact in a similar way!
As it turns out, the answer is yes! To make this neural touch-screen ensemble, I’ve used a large collection of collaborative touch-screen performance data to model ensemble interactions and to synthesise ensemble performances. These performances were free-improvisations, gestural explorations between tightly interacting performers of synthesised sounds, samples, and field recordings. In this context, the music theory of melody and harmony doesn’t help much to understand what is going on. A data-driven strategy for musical representation is required. Machine learning (ML) is an ideal approach, as ML algorithms can learn from example, rather than from theory.
In this article, I’ll explain the parts of this system but first, here’s a demonstration of what it looks like:
Live Interaction with a Neural Network
The rough idea of the neural touch-screen ensemble is this: one human improvises music on a touch-screen app and an ensemble of computer-generated ‘musicians’ reacts with their own improvisation. This system works as follows:
- First, a human performer plays PhaseRings on an iPad. Their touch-data is classified into one of a small number of touch gestures using a system called Metatone Classifier.
- Next, a recurrent neural network, Gesture-RNN, takes this lead gesture and predicts how an ensemble might respond in terms of their own gestures, this is described in more detail below.
- The touch-synthesiser then searches the corpus of performance data for sequences of touches that match these gestures and sends them to the other iPads which also run PhaseRings.
- Finally, the ensemble iPads ‘perform’ the sound (and visuals) from these sequences of touches, as if a human were tapping on their screens.
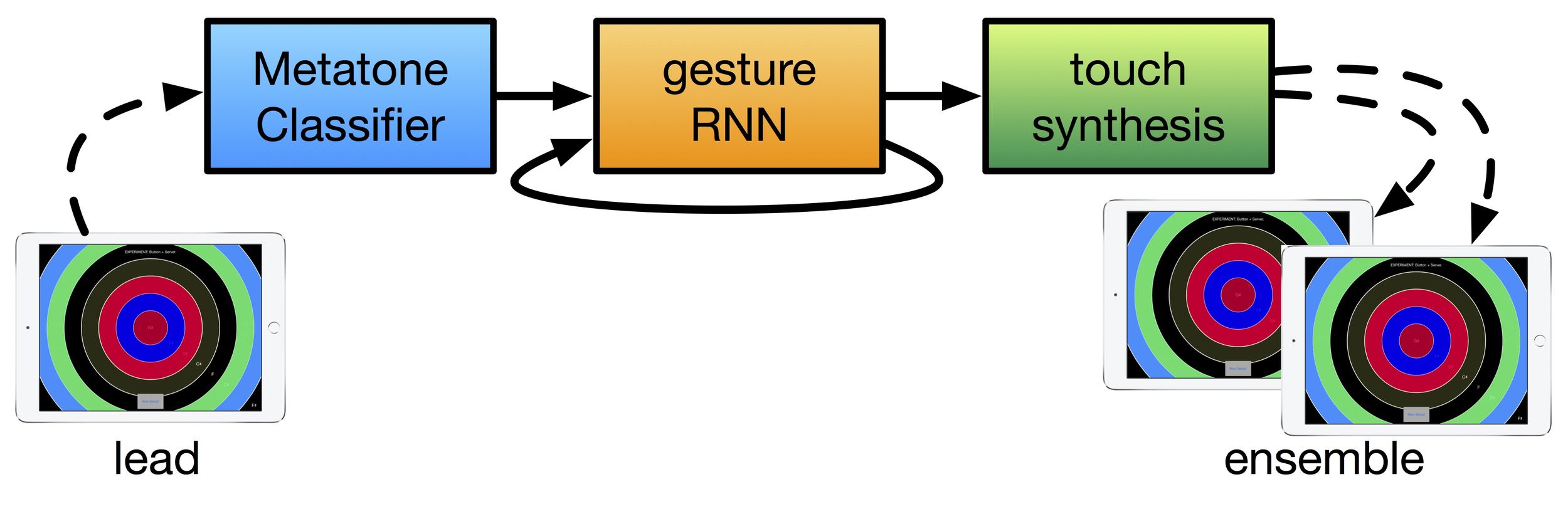
One cool thing about this system is that the ‘fake’ ensemble members sound quite authentic, as their touches are taken directly from human-recorded touch data. The totality of these components is a system for co-creative interaction between neural network and human performer. The neural net responds to the human gestures, and in turn, the live performer responds to the sound of the generated ensemble iPads. This system is currently used for in-lab demonstrations and we’re hoping to show it off at a few events soon!
Learning Gestural Interaction
The most complex part of this system is the Gesture-RNN at the centre. This artificial neural network is trained on hundreds of thousands of excerpts from ensemble performances to predict appropriate gestural responses for the ensemble.
In improvising touch-screen ensembles, the musicians often work as gestural explorers. Patterns of interaction with the instruments and between the musicians are the most important aspect of the performances. Touch-screen improvisations have been previously categorised in terms of nine simple touch-gestures, and a large corpus of collaborative touch-screen performances is freely available. Classified performances consist of sequences of gesture labels (numbers between 0 and 8) for each player in the group - similar to the sequences of characters that are often used as training data in text-generating neural nets.
Like other creative neural nets, such as folkRNN and charRNN, Gesture-RNN is a recurrent neural network (RNN) with long short-term memory (LSTM) cells. These LSTM cells preserve information inside the network, acting as a kind of memory, and help the network to predict structure in sequences of multiple time-steps. The difference between character-level RNNs and this system is that Gesture-RNN is trained to predict how an ensemble would react to a single performer, not what that lead performer might do next.
Training data for Gesture-RNN consists of time series of gestural classification for each member of the group at one second intervals. The network is designed to predict the ensemble response to a single ‘lead’ sequence of gestures. So in the case of a quartet, one player is taken to be the leader, and the network is trained to predict the reaction of the other three players.
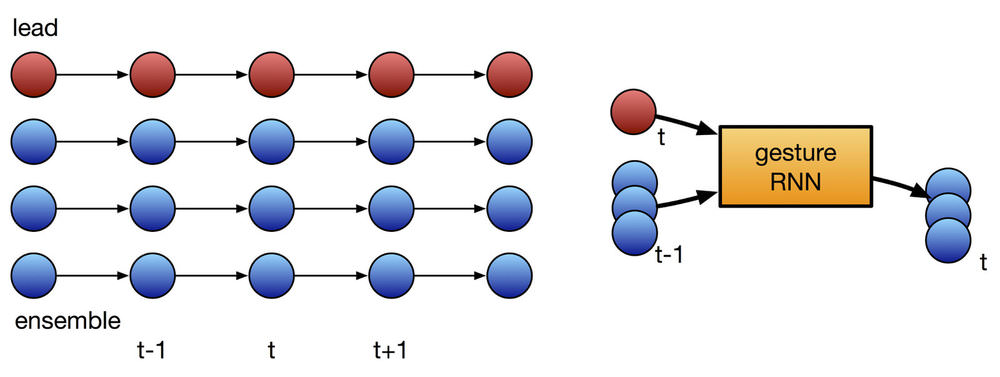
In this case, the input for the network is the lead player’s current gesture, and also the previous gestures of the other ensemble members. The output of the network is the ensemble members’ predicted reaction. This output is then fed back in to the network at the next time-step.
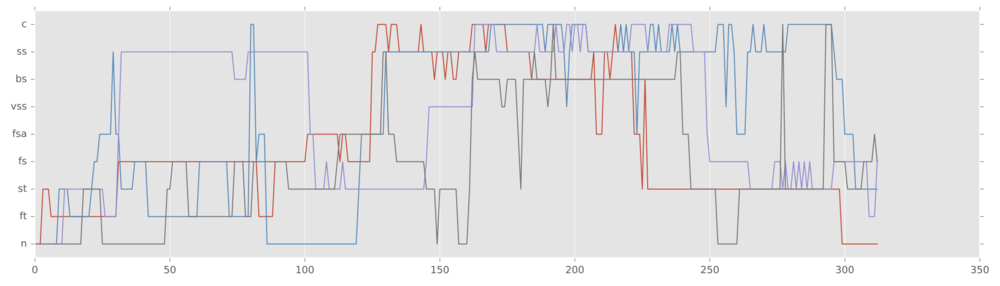
Here’s an example output from Gesture-RNN. In these plots, a real lead performance (in red) was used as the input and the ensemble performers (other colours) were generated by the neural net. Each level on the y-axis in these plots represents a different musical gesture performed on the touch-screens.
Gesture-RNN is implemented in Tensorflow and Python. It’s tricky to learn how to structure Tensorflow code and the following blog posts and resources were helpful:
- WildML: RNNs in Tensorflow, a practical guide,
- R2RT: Recurrent Neural Networks in Tensorflow,
- AI Codes: Tensorflow Best Practices,
- Géron: Hands-On Machine Learning with Scikit-Learn and Tensorflow.
Recurrent Neural Networks and Creativity
Gesture-RNN uses a similar neural network architecture to other creative machine learning systems, such as folkRNN, Magenta’s musical RNNs, and charRNN. It has recently become apparent that recurrent neural networks, which can be equipped with “memory” cells to learn long sequences of temporally-related information, can be unreasonably effective. Creative neural network systems are beginning to be a bit of a party trick, like the amusingly scary NN-generated Christmas carol. In the case of high-level ensemble interactions, we don’t have tools (like music theory) to help us understand and compose them, so a data-driven approach using RNNs could be much more useful!
The neural touch-screen ensemble is a unique way for a human performer to interact with a creative neural network. We’re using this system in the EPEC (Engineering Predictability with Embodied Cognition) project at the University of Oslo to evaluate how a predictive RNN can be engaged in co-creation with a human performer. In our current application, the synthesised touch-performances are played back through separate iPads which embody the “fake” ensemble members. In future, this system could also be integrated within a single touch-screen app, and it might allow individual users to experience a kind of collaborative music-making. It might also be possible to condition Gesture-RNN to produce certain styles of responses, that model particular users, or performance situations.
The code for this system is available online:
While there are lots of creative applications of recurrent neural networks out there, there aren’t too many examples of interactive and collaborative RNN systems. It would be great to see more creative and interactive systems using these and other neural net designs!